PostgreSQL (Postgres), is a powerful relational database that can store a wide range of data types and data structures. When it comes to storing graph data structures we might reach for a database marketed for that use case like Neo4J or Dgraph. Hold your horses! While Postgres is not generally thought of when working with graph data structures, it is perfectly capable to store and query graph data efficiently.
Understanding Graph Data Structures
Before we introduce Postgres as a graph database we need to know what a graph data structure is. A graph, or a graph data structure, is a collection of nodes and edges, where each node represents an entity or “thing”, and each edge represents the relationship between two nodes.
To think about graphs in terms of code, we may write TypeScript that looks like this:
class Node {
edges: Edge[] = [];
data: string;
}
class Edge {
previousNode: Node;
nextNode?: Node;
}Each node contains a list of its edges, and each edge contains a reference to the next/previous node. As we’ll see in SQL later, the nodes don’t always need to know about their edges.
Facebook is a popular social media platform that uses a graph to represent people and their relationships. A person can have friends, and those friends also have their list of friends. Each person is represented as a node, and each friendship would be represented as an edge. Graphs are used to model a lot of different applications like your npm dependencies, workflows, transportation systems, manufacturing lines, and more!
Storing Graph Data Structures in Postgres
To store a graph in Postgres we only need to create two tables: nodes and edges.
The nodes table will store information about each entity, while the edges table will store information about the relationships between entities.
Let’s start by creating a nodes table:
CREATE TABLE nodes (
id SERIAL PRIMARY KEY,
data VARCHAR(255)
);The nodes table we defined here has two columns: id and data. The id column is an auto-incrementing integer that serves as the primary key for the table. The data column is a string that stores any extra data associated with the node.
For this example, we’re keeping it simple and only storing a string column, but in real-world applications, this table could be anything and have any number of columns.
The most important table when creating a graph data structure is the edges table:
CREATE TABLE edges (
previous_node INTEGER REFERENCES nodes(id),
next_node INTEGER REFERENCES nodes(id),
PRIMARY KEY (previous_node, next_node)
);Here, we are creating two columns, previous_node and next_node, that represent our relationships between nodes.
Each of these columns represents a foreign key to a node. The important take away is an edges table references two rows in the same table.
An edge can only have one previous_node and next_node pairing, so we are using a composite primary key to ensure that each edge is unique and cannot reference itself.
With our tables created, we can now insert data into them.
INSERT INTO nodes (data) VALUES ('Bob');
INSERT INTO nodes (data) VALUES ('Hank');
INSERT INTO nodes (data) VALUES ('Jeff');And then let’s connect our nodes with edges:
INSERT INTO edges (previous_node, next_node) VALUES (1, 2);
INSERT INTO edges (previous_node, next_node) VALUES (1, 3);| nodes | |
|---|---|
| id | data |
| 1 | Bob |
| 2 | Hank |
| 3 | Jeff |
| edges | |
|---|---|
| previous_node | next_node |
| 1 | 2 |
| 1 | 3 |
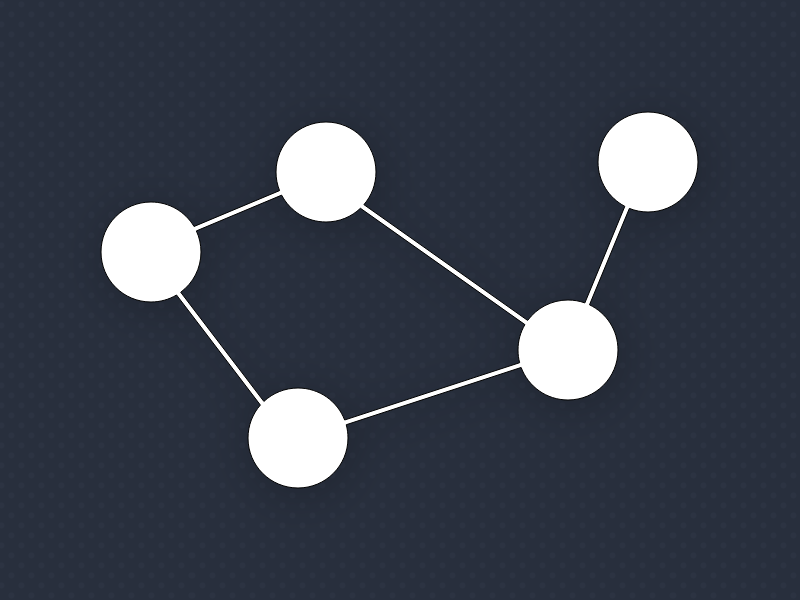
If we were to visualize our graph at this point, it would look like this:

Querying Graph Data Structures in Postgres
With our graph data structure created, we can now query it using SQL we know and love!
Want to know who Bob is friends with?
SELECT id, data
FROM nodes
JOIN edges ON nodes.id = edges.next_node
WHERE edges.previous_node = 1;Find all nodes connected to the node with id 1 (Bob’s id).
Looks like Bob is popular! But what if we want to know who Bob’s friends are friends with?
Let’s insert a few more nodes and edges to show this:
INSERT INTO nodes (data) VALUES ('Sally');
INSERT INTO nodes (data) VALUES ('Sue');
INSERT INTO nodes (data) VALUES ('Sam');
INSERT INTO edges (previous_node, next_node) VALUES (2, 4);
INSERT INTO edges (previous_node, next_node) VALUES (3, 4);
INSERT INTO edges (previous_node, next_node) VALUES (4, 5);| nodes | |
|---|---|
| id | data |
| 1 | Bob |
| 2 | Hank |
| 3 | Jeff |
| 4 | Sally |
| 5 | Sue |
| 6 | Sam |
| edges | |
|---|---|
| previous_node | next_node |
| 1 | 2 |
| 1 | 3 |
| 2 | 4 |
| 3 | 4 |
| 4 | 5 |
To query for all Bob’s friends of friends we could extend the previous query to join the edges table again, but that would cause a maintenance nightmare having to join on each “level” in the graph.
Postgres has a built-in feature that allows us to query graph data without having to know exactly how many joins we need: recursive queries. Recursive queries allow us to traverse the graph starting from a specific node and following its edges until some determined endpoint.
Writing a recursive query to find all Bob’s friends and their friends we would write the following SQL:
WITH RECURSIVE friend_of_friend AS (
SELECT edges.next_node
FROM edges
WHERE edges.previous_node = 1
UNION
SELECT edges.next_node
FROM edges
JOIN friend_of_friend ON edges.previous_node = friend_of_friend.next_node
)
SELECT nodes.data
FROM nodes
JOIN friend_of_friend ON nodes.id = friend_of_friend.next_node;This can be confusing at first glance, so let’s break it down. A recursive query is made up of two parts: the base case and the recursive case. The base case is where we want to start our query. The recursive case is the “loop” that will continue to run until some endpoint is reached.
WITH RECURSIVE {name} AS (
{base case}
UNION
{recursive case}
)The basic SQL structure of a recursive query.
In our example we want to start our query with Bob’s friends, so we find the edges where Bob (id: 1) is the previous_node.
Then in the recursive case we continually join the edges table to itself until we reach the end of Bob’s graph (eg. when we reach friend_of_friend.next_node = NULL).
Finally outside our recursive query we bring it all together. We need to query the nodes that are associated with the edges from the recursive query so we can get each of Bob’s friends’ names.
| data |
|---|
| Hank |
| Jeff |
| Sally |
Conclusion
By using features built into Postgres, we can store and query graph data structures. We used a similar approach in my previous job to dynamically generate work instructions on a manufacturing line. Based on parameters given, and rules defined on each edge, we could generate the correct document by traversing a graph stored entirely in Postgres. If you are already using Postgres for your relational data, you can integrate graph data structures into your existing database without adding extra systems!